|
I am currently a researcher at Mozilla. This page was last updated in December 2013. I was then a visiting research scientist at the Allen Institute for Artificial Intelligence. I received my Ph. D. in Computer Science from Stanford University, working with Jeffrey Heer and Christopher D. Manning, and was a post-doctoral researcher at the University of Washington. My research on data analytics focuses on the design of interactive visualizations and statistical models to enable people and algorithms to work in tandem to yield insights from complex data. My work has appeared in top-tier venues in human-computer interaction (CHI, TOCHI), machine learning (ICML), and natural language processing (EMNLP), and has contributed to publications in multiple disciplines including social sciences and genetics research. CALL FOR PAPERS: I am organizing the Workshop on Interactive Language Learning, Visualization, and Interfaces at ACL 2014. Our goal is to assemble an interdisciplinary community that promotes collaboration across natural language processing, human-computer interaction, and information visualization. We would like your input! | Contact +1 (646) 450-9795 jason.chuang.info Affiliations Mozilla Allen Institute for AI UW Interactive Data Lab Stanford NLP Group Stanford HCI Group Information Curriculum Vitae Google Scholar Profile |
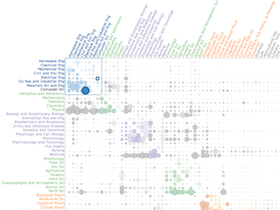
 | Topic Model DiagnosticsAnalytics ML HCI My ICML 2013 paper introduces a framework for large-scale evaluation of statistical topic models, learning algorithms, and topical quality measures. We surveyed and analyzed how experts organize concepts in their domain of expertise. Based on human analytic strategies, we formalized four categories of topical misalignments representing the full range of errors that can occur when matching model outputs to a set of reference concepts. We examined topic models built using 10,000 parameter settings and evaluated the performance of hyper-parameter optimization, inference algorithms, and intrinsic measures of topical quality. |
 | Sentiment Classification and VisualizationAnalytics Vis ML Domain At EMNLP 2013, we presented a deep learning algorithm that achieves the current highest accuracy in sentiment classification of sentences. During algorithm development, we applied visual analytics to investigate how well our technique captures the effects of sentiment negations. My visualizations enabled more rapid exploration of manually-labeled sentiment datasets, and revealed patterns of negations. I incorporated interactions, such as highlighting sentences in which the linguistic signifiers of negations are situated far apart, to help machine learning researchers gain insights about the model. |
 | Termite: Topic Model VisualizationAnalytics Vis ML HCI Domain As originally introduced at AVI 2012 with updates to appear at a NIPS 2013 workshop, I designed Termite, a visual analysis tool for builders and users of statistical topic models. My tool enables more rapid and accurate evaluation of model quality. We incorporate a matrix view to support the assessment of topical term distributions and aid the comparison of latent topics. We developed a seriation algorithm that arranges words to reveal the clustering of related terms and promote the legibility of multi-word phrases. We devised a saliency measure to highlight distinctive vocabulary. |
 | Design of Model-Driven VisualizationsAnalytics Vis ML HCI Domain At CHI 2012, I presented a set of principles and processes for designing model-driven visualizations. I described my experiences building the Dissertation Browser, a tool for investigating the impact of inter-disciplinary collaborations at Stanford University. During tool development, we sought expert feedback, and jointly explored modeling capabilities and visual designs to address interpretation and trust issues that hinder analysis. Our iterative design process led to a novel “word borrowing” algorithm, judged as the most accurate by domain experts, outperforming all other models considered at the start of the analysis. |
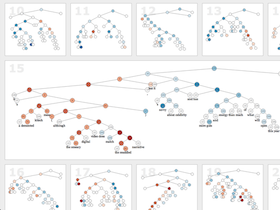
 | Mapping Intellectual Changes in AcademiaAnalytics Vis ML Domain We mapped the evolution of 30 years of academic discourse based on topical analysis of 1.05 million Ph.D. dissertations. My visualizations helped machine learning researchers verify model stability, and allowed collaborating social scientists to test alternative hypotheses and verify their discoveries. Part of this work is to appear in our upcoming Poetics 2013 article. |
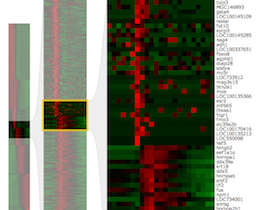 | Frog Gene VisualizationVis Domain I developed an interactive visualization, the Transcriptome of Xenopus Tropicalis, for exploring 24,000 genes belonging to the frog genus Xenopus. The tool is presented in our Genome Research 2013 article. |
 | Descriptive KeyphrasesAnalytics Vis ML HCI I studied how people summarize text using descriptive phrases, and developed a novel algorithm for extracting keyphrases from documents. In my TOCHI 2012 article, we described our user study on human-generated keyphrases. We systematically examined linguistic features predictive of high-quality summary terms, and developed a model to automatically extract descriptive phrases from text. We identified issues of specificity and redundancy through crowd-sourced user evaluations, and proposed additional algorithms to support adaptive selection of keyphrases. We demonstrated novel text visualizations enabled by our algorithms. |
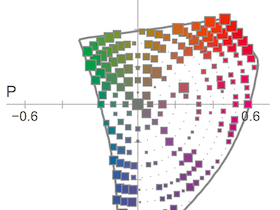 | Color CategoriesVis HCI I devised a probabilistic model for quantifying the effects of languages on color perception, based on an analysis of the World Color Survey and English color naming data collected on the web. In my CIC 2008 paper, we demonstrated that the model can identify well-named regions of the color space. |